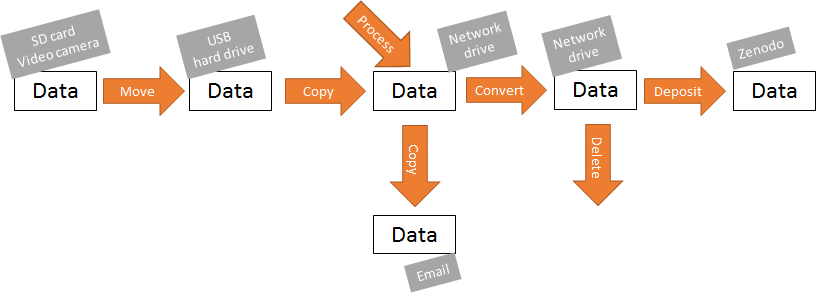
The main goal of this toolkit is to enable you to visualize the life cycle of your research data, as well as to talk about the consequences of your choices. Generic life cycle models and data management plans can easily be too broad to grasp the complexity of handling data. For instance, when loosing important parts of your data, because you did not have a copy of your raw data; or when referring to metadata as a static thing, when it is actually added and/or removed throughout the entire life cycle depending on the context of the data.
The intention is that you make a print of the toolkit, or use a white board or similar, to visualize your data flow.
The toolkit is divided into three parts; data objects, processes, and systems. Data objects are the basic puzzle element of the toolkit. Data objects can be any type of data, and you decide the level of abstraction. Data objects are stored on a system. Processes are used to link data objects together, e.g. creating a copy of a data set. Processes can also be cyclic on a single data object, e.g. modifications to a data set.